My master data table
One of the first tasks I was given when I started in my current position in July 2012 was to be the lead faculty for a non-majors introductory biology course. That course is one of the workhorses of the university as it is part of the GE curriculum, and it is basically the one and only science class most non-science majors will take. Run in several sections in multiple campuses and online, it was a formidable task to tackle. When I took over, the course had been in place with the same textbook for many years, and especially in the online version, plagiarism was rampant.
Over the next months I explored options for a new textbook, mainly looking for something fresh and attractive, with plenty of ready-made supplementary material, low(er) cost, and options to customize. I wanted something that was “ready-made” enough for a new adjunct to tackle, but flexible enough for an experienced instructor to make changes. An instructional designer helped me to develop a nice sequence of activities and assessments that would go hand in hand guiding the students. Weekly quick surveys were added to pick up any early student issues. I asked instructor feedback, and in August 2013 we switched. I expected to see a positive change right away.
Chuckle.
My university’s accelerated schedule means that we run the course monthly in multiple sections. So there was no real time off to test drive the system. The first months were full of glitches and student frustration. Some instructors kept their old exams with the new textbook, resulting in vociferous protests for lack of matching between material read and material evaluated. Things calmed down over the next months and currently the course runs quite smoothly.
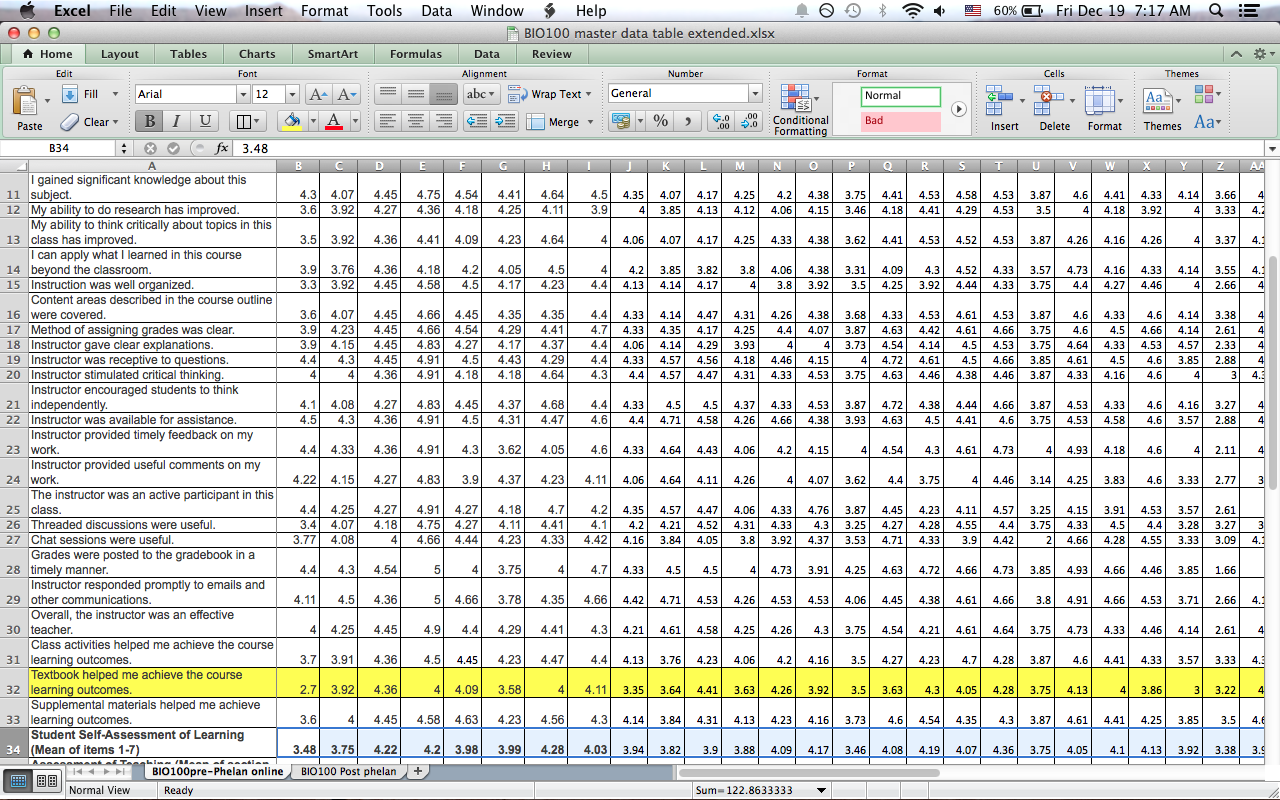
A few months ago I decided to use the large amount of data generated to compare before and after. I had student end-of-course survey and GPA data easily accessible, as well as a number of assessment data with the new course and tons of (anonymous) student comments.
What I learned:
- Student survey data don’t mean anything. This is not new of course, but it did hit me with full force going over the numbers of 40 something courses. Response rate was usually around 50% in the best case. The few cases that it was higher it was usually due to issues with the instructor.
- With the above I mean not only that there was no difference in student perception, but that the data were not really robust. If the same instructor who has been teaching the same class forever gets really different evaluations in back to back courses, chances are there are confounders. One can be different student population. Other may be just sampling bias (who answers the surveys?) A colleague with biostatistics experience is lending me a helping hand as we speak.
- The hardest lesson of course, was not keeping some of the previous assessment questions in place to compare. However, I do not really know it would have been feasible. The written assignments were so plagiarized that they could be found online. The exams were straight multiple choice questions. In any case, for a flipped classroom project I am participating now I had the precaution of designing a few strategic critical thinking questions placed in the “unflipped” class serving as control.
- Not all is lost of course. As I learn more about how to analyze education experiments, I have been given some ideas, such as rank the students and compare their grade in the biology class and then the grade in a subsequent lab class. Maybe the approach does not help high achieving students (who will do well no matter what), but there may be some difference in the low achieving group.
Of course even negative results are results, but it would be nice to see “something” improving. The only factor that moved significantly in the positive direction was the students’ opinion about the textbook. Will see how the next round if data crunching goes…
Dear readers, do you have any insight/advice about measuring learning effectiveness? Please share in the comments…any help is much appreciated.



