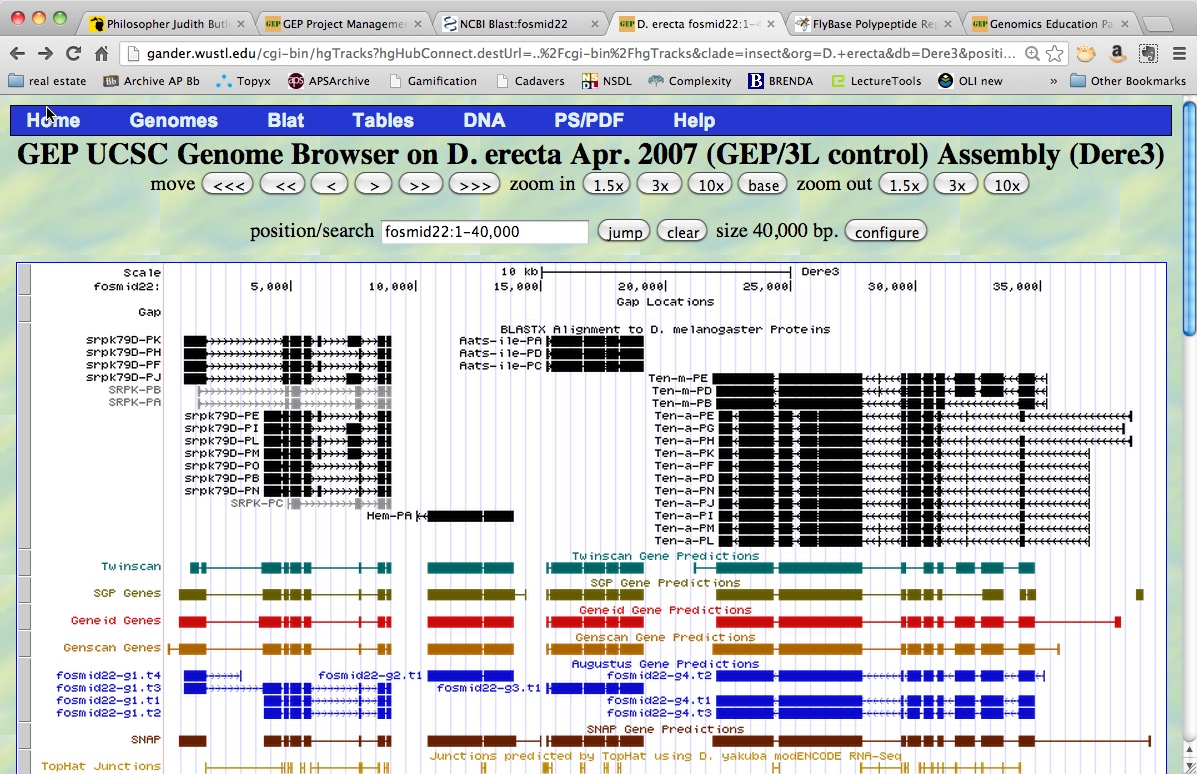
A screenshot from today’s annotation.
Well, it is almost 11 pm and I am catching up with emails and blog posting at the hotel lobby. As Sally promised, the day was indeed intense. Once inside the computer lab of the Biology building, we sat down facing shiny large Apple displays (all analysis takes place on Macintosh computers, to some chagrin of the PC-only crowd) and started to crank. Actually we started with an intro lecture about annotation of Drosophila species, which is the first powerpoint here. This particular project is based on Drosophila, a model organism that I have never touched in my life except for illustration of some classic genetics concepts and experiments. But the way the project is designed, the workflow is applicable to other systems. We were given a basic annotation workflow suggestion:
- Identify the likely ortholog in D. melanogaster
- Determine the gene structure of the ortholog
- Map each exon of ortholog to the project sequence
- Use BLASTX to identify conserved region
- note position and frame
- Use these data to construct a gene model
- Identify exact start and stop base position for each CDS
- Use the Gene Model Checker to verify the gene model
- For each additional isoform, repeat steps 2-5
So we claimed fosmids containing genomic sequences from different Drosophila species,and started to play. The Gene Browser used is a mirror of the UCSC gene browser, once we get the alignment, we start to map the genes.
For me, newbie as I am to the whole business, it was amazing how real things become, once you are actually using the information to achieve a goal. For example, the realization that a piece of DNA has indeed 6 ways to be read, depending on the reading frame. That introns indeed exist and have to match the beginning and the end showing the donor (GT) and acceptor (AG) sequences. That codons can be interrupted by introns and one has to check, zooming in deep to the nucleotide level, that it is completed afterward. But as many said, the gamelike feeling of the beginning should be promptly corrected with the deep science behind those sequences. The biology, the conservation, the function of genes and the proteins they encode, are all aspects to be considered when annotating DNA.
I felt profound empathy with my students today. How many times, after going over some deep and complicated topic, I would give them 5 minutes to discuss and practice, and then move on to the next topic? I realize now how important is to pause, and give students time to go over the motions, to practice and just be able to process the information. Luckily we had breaks, and sometimes I just had to politely shoo away the helpful TAs. I needed time for myself, to try to do it on my own, and then ask questions.
There were discussions of many aspects of annotation today, how to handle gene families, repeats, and even transposable elements. I took notes, and asked questions. Luckily, I did not beat myself up choosing a too complicated assignment- I chose a relatively easy one, which gave me some satisfaction. I guess after some years brushing with teaching faculty I learned about scaffolding 🙂 Tomorrow will be another day…
The night ended (after dinner) with a discussion of possible ways of implementation. Many ideas were offered, from research courses to research retreats, or even modules in lower and upper level classes. My reflection was about how to incorporate this into a molecular bio or even gen bio class from day 0- start looking at real sequences from the moment the concepts are introduced. Maybe too steep a learning curve? I will have to think about a good strategy to implement. On the other hand, it could be part of an arc of application to the different levels of biological concepts from gene to protein.
And this is all for today, dear readers…am fading. Good night!

Leave a comment